This post is going to be short. Basically, CartoDB runs on the coolest database in the world, PostgreSQL. Because it runs on such an amazing open source technolgy, we often get to tap into amazing advances and amazing documentation of methods that come from the community.
One really nice write-up I came across over the week was, Full text search in milliseconds with PostgreSQL by Max Novakovic. If you haven’t read the post, it just shows you the handful of steps you need to take in order to make really fast, full text search possible in your PostgreSQL tables. I read the post and was like, “CartoDB readers need to know this”.
If you didn’t know, no matter type of CartoDB account you use, you have the ability to create functions and triggers that work on your tables that generate your maps. Given this flexibility, we can follow Max’s write-up for full text search directly in the CartoDB Editor.
Full text search on CartoDB
I have a really nice dataset from a weekend hack I did a couple years back. Basically, it is a bunch of (poorly) georeferenced text from the complete works of Mark Twain. You can find the complete dataset over on my public profile page.
Okay, given a table named twain in my account, and two columns of text, name which is the placename identified and passage which is the fulltext of the line geocoded, let’s replicate the steps to make fast full text search possible.
Adding columns and indexes
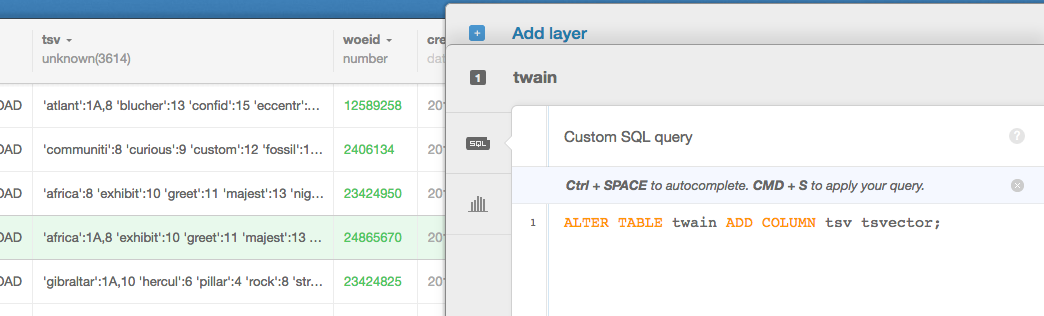
Right in the CartoDB Editor, we are going to run the following SQL statements one at a time.
ALTER TABLE twain ADD COLUMN tsv tsvector;and then
CREATE INDEX twain_tsv_idx ON twain USING gin(tsv);When adding indexes in CartoDB, I often include the name of the table directly in my index name, twain_tsv_idx for example. I do this so that I don’t hit the same index name twice if I use it on multiple tables. I don’t imagine this will be my last tsv example, so it will be good to do here.
Updates - setting our tsvector values
Just like addeing columns and indexes in CartoDB, we can run UPDATEs directly in the editor. Here we are going to follow Max’s method, but we aren’t using a JSON column as input, I’m just using my two text columns name and passage, so my query looks a little bit different.
UPDATE twain SET
tsv =
setweight(to_tsvector(coalesce(name,'')), 'A') ||
setweight(to_tsvector(coalesce(passage,'')), 'D');Creating functions and triggers
Creating functions and triggers is just as easy, write them directly in the SQL editor in your account, hit apply query and if no errors are returned, you are gold. Again, I’m going to add the tablename to my function to ensure I don’t clash with future functions.
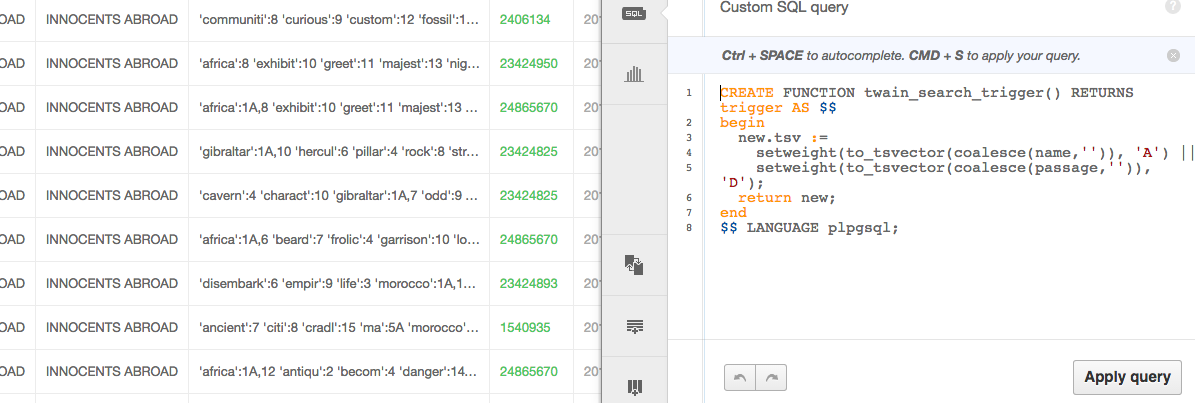
CREATE FUNCTION twain_search_trigger() RETURNS trigger AS $$
begin
new.tsv :=
setweight(to_tsvector(coalesce(name,'')), 'A') ||
setweight(to_tsvector(coalesce(passage,'')), 'D');
return new;
end
$$ LANGUAGE plpgsql;Same thing for creating our INDEX,
CREATE TRIGGER twain_tsvectorupdate
BEFORE INSERT OR UPDATE
ON twain FOR EACH ROW EXECUTE PROCEDURE documents_search_trigger();Running a full text query
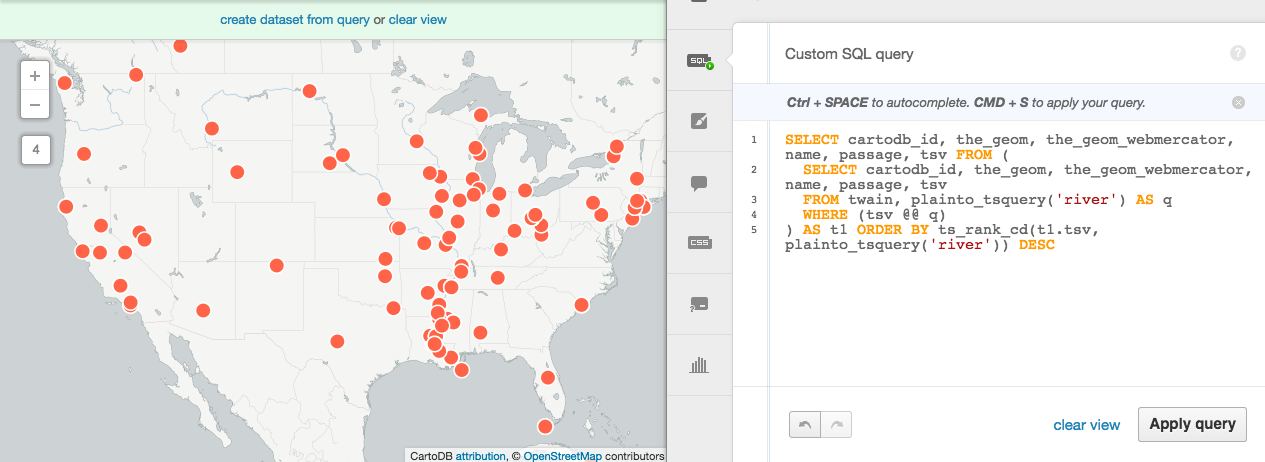
Final thing is to see it in action. Here, I’m going to query for Mark Twain passages that include the phrase, river,
SELECT cartodb_id, name, passage, tsv FROM (
SELECT cartodb_id, name, passage, tsv
FROM twain, plainto_tsquery('river') AS q
WHERE (tsv @@ q)
) AS t1 ORDER BY ts_rank_cd(t1.tsv, plainto_tsquery('river')) DESC Here we can see it in action,
And if you are building an application, you can run the same query over the SQL API to retrieve the data as a JSON object.